Samstag, Juni 16, 2012
Tino forscht
 Nach diversem Hinundher
bastle ich weiter am "Medienbotenkatalog auf AppEngine". Trotz der guten Apache-Bibliothek
POI/HSSF um Excel-Daten zu verarbeiten, kommt man bei den
Ausgangsdateien zu so einfachen wie grundsätzlichen Fragen: Wann ist
Schwarz eigentlich Schwarz? Wer definiert hier in welcher Palette, dass
Font.COLOR_NORMAL Schwarz bedeutet? Und wieso hält sich die Datei nur
manchmal daran? Zugegebenermaßen sind die Daten verschieden formatiert,
aber immer irgendwie Schwarz - technisch leider nicht :-(
Nach diversem Hinundher
bastle ich weiter am "Medienbotenkatalog auf AppEngine". Trotz der guten Apache-Bibliothek
POI/HSSF um Excel-Daten zu verarbeiten, kommt man bei den
Ausgangsdateien zu so einfachen wie grundsätzlichen Fragen: Wann ist
Schwarz eigentlich Schwarz? Wer definiert hier in welcher Palette, dass
Font.COLOR_NORMAL Schwarz bedeutet? Und wieso hält sich die Datei nur
manchmal daran? Zugegebenermaßen sind die Daten verschieden formatiert,
aber immer irgendwie Schwarz - technisch leider nicht :-(
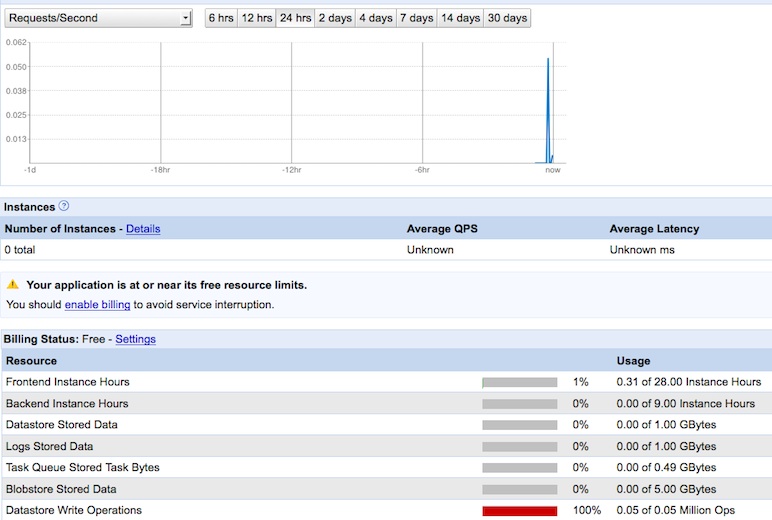
Wenn man dann alles gefärbt hat, kann man sehe, wie fleissig/ineffizient ich Datenbank-Operationen gebaut habe - innerhalb von 5min alles verbraucht - "Your application is near is free resource limit" - also einen Tag warten und bis dahin besser werden, d.h. Batch-Operationen beachten.
Donnerstag, Mai 24, 2012
OrmHate
 Irgendwie hat MF
immer die richtigen Dinge zu sagen: Gerade ist bei uns eine DBA vs.
Dev-Team-Diskussion entfacht und sie dauert noch an.
Irgendwie hat MF
immer die richtigen Dinge zu sagen: Gerade ist bei uns eine DBA vs.
Dev-Team-Diskussion entfacht und sie dauert noch an.
Many people treat the relational database "like a crazy aunt who's shut up in an attic and whom nobody wants to talk about"[3]. In this world-view they just want to deal with in-memory data-structures and let the ORM deal with the database.
Unsere Tante heisst Onkel Torsten; und ja, ich bin im Prinzip auch der Ansicht, dass die DB das Objekt-Modell unterstützen soll und nicht umgedreht.
Es wird hoffentlich weniger hässlich als Vietnam, aber dieses Essay hat einige Zustände sehr prägnant zusammen gefasst:
Discussions of inheritance-to-table and association mapping schemes also reveals a basic flaw: At heart, many object-relational mapping tools assume that the schema is something that can be defined according to schemes that help optimize the O/R-M's queries against the relational data. But this belies a basic problem, that often the database schema itself is not under the direct control of developers, but instead is owned by another group within the company, typically the database administration (DBA) group.
In many cases, developers begin a new project with a "clean slate", an empty relational database whose schema is theirs to define as they see fit. But, soon after the project has shipped, it becomes apparent that the developers' ownership of the schema is temporary at best--various departments begin clamoring for reports against the database, DBAs are held accountable to the performance of the database thereby giving them cause to call for "refactoring" and denormalization of the data... Before too long, the schema must be "frozen", thereby potentially creating a barrier to object model refactoring ... In addition, these other teams will expect to see a relational model defined in relational terms, not one which supports an entirely orthogonal form of persistence--for example, the "discriminator" column ...
So, then, the next task is to create a "Query-By-Language"
approach, in which a new language, similar to SQL but "better" somehow,
is written to support the kind of complex and powerful queries normally
supported by SQL
The problem here is that frequently these languages
are a subset of SQL and thus don't offer the full power of SQL.
Was bleibt also: Es gibt viele Wege nach Rom - der gutklingende führt interessanterweise als Beispiel db4o an, ein OO-Datenbanksystem, mit dem wir 2008 mächtig baden gegangen sind.
Summary: Wholehearted acceptance. Developers simply give up on relational storage entirely, and use a storage model that fits the way their languages of choice look at the world. Object-storage systems, such as the db4o project, solve the problem neatly by storing objects directly to disk. ... While many DBAs will faint dead away at the thought, in an increasingly service-oriented world ... it becomes entirely feasible to imagine developers storing data in a form that's much easier for them to use, rather than DBAs.
Andere, eher elementare aber trotzdem gut illustrierte Fakten zum Object-Relational Impedence Mismatch :
Object systems are typically characterized by four basic
components: identity, state, behavior and encapsulation
[Date04] and
[Fussell] define the relational model as characterized by relation,
attribute, tuple, relation value and relation variable.
JOINs are among the most expensive expressions in RDBMS
queries.... As a result, developers typically adopt one of the other two
approaches ...: they either create a table per concrete (most-derived)
class, preferring to adopt denormalization and its costs, or else they
create a single table for the entire hierarchy, often in either case
creating a discriminator column to indicate to which class each row in
the table belongs.
Unfortunately, the denormalization costs are often
significant for a large volume of data, and/or the table(s) will contain
significant amounts of empty columns, which will need NULLability
constraints on all columns, eliminating the powerful integrity
constraints offered by an RDBMS.
Inheritance mapping isn't the end of it; associations between objects, the typical 1:n or m:n cardinality associations so commonly used in both SQL and/or UML, are handled entirely differently: in object systems, association is unidirectional, from the associator to the associatee ..., whereas in relational systems the association is actually reversed, from the associatee to the associator (via foreign key columns).
Allgemeine Regeln oder Grundsätze werden auch gestreift: Law of Diminishing Returns, "the Slippery Slope", "the Drug Trap", "the Last Mile Problem"
Donnerstag, April 26, 2012
Vaadin
 Meine Versuche mit GWT/GAE/Roo sind ins Stocken geraten - das unreife
Zusammenspiel von roo und GAE, welches die komplizierte Architektur von
GWT mit zig Klassen mit echtem Boilerplatecode für ein simples Frontend
halbwegs akzeptabel machen könnte, hat den Ausschlag gegeben: Am Ende
kommt eine Menge Code heraus, der nicht übersichtlich und erweiterbar
ist sondern irgendwie die eigentliche Domäne vernebelt....
Meine Versuche mit GWT/GAE/Roo sind ins Stocken geraten - das unreife
Zusammenspiel von roo und GAE, welches die komplizierte Architektur von
GWT mit zig Klassen mit echtem Boilerplatecode für ein simples Frontend
halbwegs akzeptabel machen könnte, hat den Ausschlag gegeben: Am Ende
kommt eine Menge Code heraus, der nicht übersichtlich und erweiterbar
ist sondern irgendwie die eigentliche Domäne vernebelt....
Aber ich will an einer Java-Hosting-Lösung festhalten, ohne einen eigenen Server zu mieten oder Amazon-Services zu nutzen (tja, warum eigentlich nicht?) - da kommt bisher als anfangs freie Variante nur GAE in Frage, wenn auch um den Preis eines NoSQL-Datastores. Aber man kann auch mal AWS anschauen:Ein eigener Server und gut, allerdings sind mir die Preismodelle unübersichtlich, dann lieber eine freie Quota bei GAE.
So nebenbei lerne ich, was was ist ("Schlagwörter: Hosting, Cloud Computing, Azure, SaaS, Amazon, 1&1, domainfactory, Online-Speicher, Google App Engine, NIST, IaaS, PaaS"), passend dazu hat die c't eine Artikelserie und kommt darin zu dem Schluss: "Google mit seiner AppEngine als Zwischending zwischen Platform-as-a-service und Software-as-a-service ist von den Dreien {EC2, MS Azure, GAE} noch am leichtesten zu beherrschen..."
Vaadin vs GWT/GAE
- klares Framework, einfache Erweiterung
- GAE nicht beste Plattform: performance, ui-state in session, server load, datastore mapping?
- ->addressbuch als beispiel, mit GAE
- plain GWT - too much boilerplate code for MVP/RFactory Model, roo code generation immature
- vaadin with good tutorial and halfway app
- Vaadin-Buch: Beispiel mit Roo und anpassbaren Views sowie deployment auf den Java-Hoster CLoudfoundry (inkl. MySQL) ( https://vaadin.com/book/-/page/rapid.cloudfoundry.html)
Vaadin-Plugin: Kurzes Beispiel mit in Memory DB (https://vaadin.com/springroo); Vaadin-Tutorial: Gute Beispielanwendung AddressBook ohne Roo ohne DB ohne Deployment.
Ach ich weiss es doch auch nicht - warum hab ich damals aufgehört, die GWT 1.x Variante zu verfolgen?
Donnerstag, März 01, 2012
State of Play

Ach ja: roo 1.2 bedingt -> GAE 1.6.0 mit datanucleus-appengine plugin 2.0.0-RC2 welches datanucleus 3.0.4 welches JPA 2.0 braucht: ätz...
Die GAE-datanucleus-Integration scheint überschattet und aktuell stark limitiert zu sein:
Unowned relations sind plötzlich nicht möglich:
testCountCustomers(de.tixus.mb.roo.gwt.shared.domain.CustomerIntegrationTest): Error in meta-data for field de.tixus.mb.roo.gwt.shared.domain.Staff.id : Cannot have a primary key of type java.lang.Long and be a child object (owning field is "de.tixus.mb.roo.gwt.shared.domain.Customer.servedBy").; nested exception is javax.persistence.PersistenceException: Error in meta-data for field de.tixus.mb.roo.gwt.shared.domain.Staff.id : Cannot have a primary key of type java.lang.Long and be a child object (owning field is "de.tixus.mb.roo.gwt.shared.domain.Customer.servedBy").
testFindCustomer(de.tixus.mb.roo.gwt.shared.domain.CustomerIntegrationTest): java.lang.Long cannot be cast to java.lang.Integer
Datanucleus weiss das und schlägt was vor, aber das hört sich kompliziert an:
By default in GAE/J all relations are owned meaning that any child objects have the parent object Key as part of their Key, and persisted as part of the same entity-group. This is obviously useful in optimising retrieval of data, but there are times when you simply want your model persisting and not have imposition of ownership. In v2 of the plugin you can have unowned relations, where each object is in its own entity-group. To define a relation like this, see the following example
@PersistenceCapable
public class A {
@Persistent(primaryKey="true",
valueStrategy=IdGeneratorStrategy.IDENTITY)
long id;
@Unowned
B
b;
}
@PersistenceCapable
public class B
{
@Persistent(primaryKey="true",
valueStrategy=IdGeneratorStrategy.IDENTITY)
long id;
@Unowned
@Persistent(mappedBy="b")
A
a;
String name;
}
So when we persist an object of type A with related B it will do
the following:
PUT the A, generating its Key, but
without property for B
PUT the B, generating its Key,
and with a property referring to the key of A
PUT the A
with the property referring to the key of B.
Jesus!
DIe JPA 2.0-Integration hat einen bug: "Result class is simple, but field value [Ljava.lang.Object;@135afd61 not convertible into that;"
Darin (verständliches) fehlendes GAE-Commitment der roo-Leute:
Given that GAE and GWT are not high on our priorities due to their restrictions of what you can do, we are expecting GAE to allow JPA 2.0 compliant applications to run like other platforms such as EclipseLink and Oracle for example.
Für eclipse fehlen die GAE, GWT runtimes
<classpathentry kind="con"
path="com.google.gwt.eclipse.core.GWT_CONTAINER"/>
<classpathentry
kind="con" path="com.google.appengine.eclipse.core.GAE_CONTAINER"/>
Kann man per Hand hinzufügen, aber dasroo-plugin
schmeisst sie immer raus:
Roo regenerates gwt-maven-plugin
in pom.xml deleting edits done by the user
Montag, Februar 27, 2012
Work bits
Hmm, muss ich mir Sorgen machen, wenn bei unseren (großenteils externen) Entwicklern sowas als Motto "Please keep quit?" im Raum hängt?!

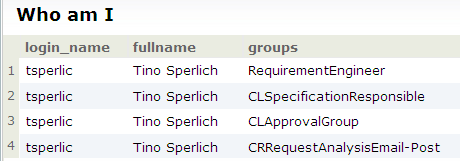
Ansonsten ist es immer gut zu wissen, wer man ist:
Und das M$Office auch lustig sein kann, beweisen diese Meldungen:

Donnerstag, Dezember 22, 2011
roo+SpringMvc
roo + SpringMVC: Fuck, ein Standard-Deploy endet so:
tsps-MacBook-Pro:mb-mvc tsp$ mvn gae:deploy -DskipTests=trueDec
21, 2011 1:51:01 PM org.apache.jasper.compiler.AntCompiler generateClass SEVERE:
Error compiling file:
/var/folders/rA/rAI3y8hfFQuztePwrkEL5U+++TI/-Tmp-/appcfg6923119542883762797.tmp/WEB-INF/classes/org/apache/jsp/tag/web/util/panel_tagx.java[javac]
Compiling 1 source file [javac] error: Bad service
configuration file, or exception thrown while constructing Processor
object: javax.annotation.processing.Processor: Provider
org.datanucleus.enhancer.EnhancerProcessor could not be instantiated:
org.datanucleus.exceptions.NucleusException: Error reading manifest file
"jar:file:/var/folders/rA/rAI3y8hfFQuztePwrkEL5U+++TI/-Tmp-/appcfg6923119542883762797.tmp/WEB-INF/lib/datanucleus-core-1.1.5.jar!/plugin.xml"
Also googlen und frickeln..... Und ja, nach dem Entfernen aller dependencies von datanucleus-enhancer loop et endlich:
tsps-MacBook-Pro:mb-mvc tsp$ mvn clean gae:deploy -DskipTests=true[INFO]
Scanning for projects... Beginning server interaction
for medienboten... 0% Created staging directory at:
'/var/folders/rA/rAI3y8hfFQuztePwrkEL5U+++TI/-Tmp-/appcfg3602209683130921361.tmp'
5% Scanning for jsp files. 8%
Compiling jsp files. Dec 21, 2011 2:15:35 PM
com.google.apphosting.utils.config.AbstractConfigXmlReader readConfigXml INFO:
Successfully processed
/var/folders/rA/rAI3y8hfFQuztePwrkEL5U+++TI/-Tmp-/appcfg3602209683130921361.tmp/WEB-INF/web.xml
20% Scanning files on local disk. 25%
Scanned 250 files. 28% Initiating update. Email:
xxx@gmail.com Password for xxx@gmail.com: 77%
Initializing precompilation... 90% Deploying new
version. 95% Will check again in 1 seconds. 98%
Will check again in 2 seconds. 99% Will check again in
4 seconds. 99% Closing update: new version is ready to
start serving. 99% Uploading index definitions. Update
completed successfully. Success.
Und Browser auf und schauen - erstmal nix, aber nachdem ich den alten Datenbestand gelöscht habe:

Bis zur nächsten Untiefe:

Ok, ein bekannter Fehler: "These break all list pages. The following exception is generated:JspException: java.lang.NoSuchMethodError: "
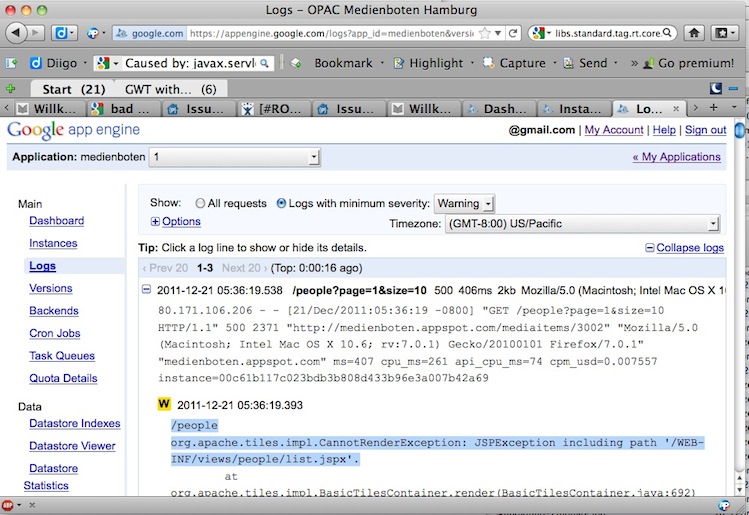
Also scope ändern und redeploy, das übt ja...
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
<scope>provided</scope><!--
Added -->
</dependency>
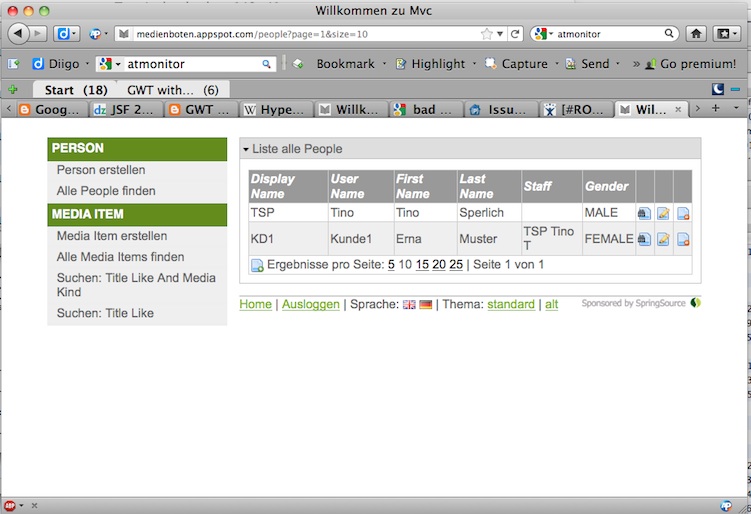
Natürlich lasse ich auch die Datastore-Fallstricke nicht aus: Index fehlt, erstmal also Beng:
Caused by:
com.google.appengine.api.datastore.DatastoreNeedIndexException: no
matching index found. The suggested index for this
query is: <datastore-index kind="MediaItem"
ancestor="false" source="manual"> <property
name="mediaKind" direction="asc"/> <property
name="title" direction="asc"/> </datastore-index>
Aber auch hier sehr gute Hilfe im Netz: datastore-indexes.xml anlegen, obige Fehlermeldung hineinkopieren, re-deploy und los:

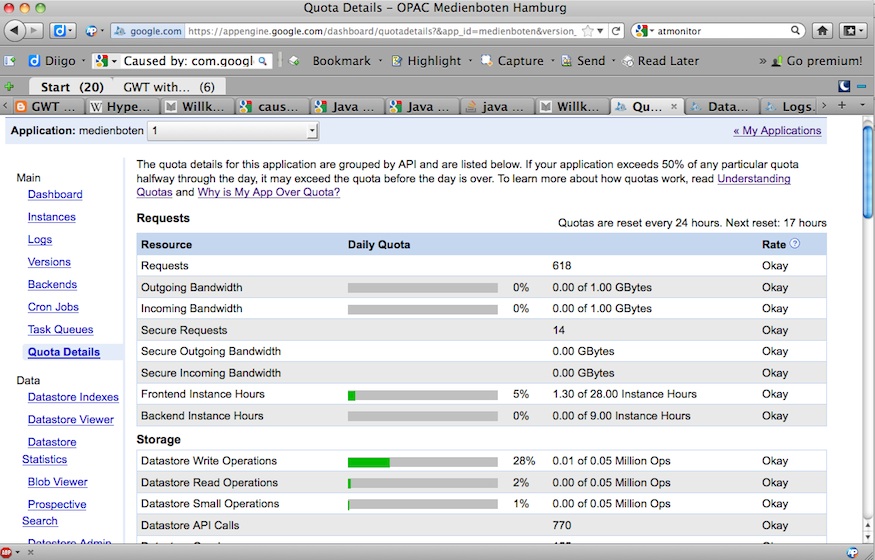
Nun muss ich mal klären, wie das mit der freien Quota läuft, also ob eine mässige Benutzung gedeckt ist oder es bald Scheine regnen muss:
Mittwoch, Dezember 21, 2011
Roo+X
Tja, ich fühle mich wie ein Hamster, der ständig den Hype-Zyklus durchrattert: Mein Hauptproblem ist es, die GUI für das Backend GAE auszuwählen; mit roo als Modellierungstool/-sprache bin ich ganz zufrieden. Aber wie weiter
- roo + GWT: nettes CRUD aber unheimlich aufwendige Implementierung des an sich guten GWT-Webmodells (Acitivities, Places)
- roo + JSF: zukunftsorientiert, aber die aktuelle roo-Version generiert nicht mal fehlerfreie poms
- roo + SpringMVC: Standard-JSP-MVC, nicht sexy aber solide, deploy-Fehler
Mal sehen, welches der Modelle ich mal durchgehend zum Laufen und deployed bekomme um gemäß dieser Folie feiern zu können:

Donnerstag, November 03, 2011
Customize spring roo gwt
Ab hier wirds anstrengend, weil, wie Cengiz sehr richtig bemerkt:
... the trouble lies beyond this point in customizing the Roo-generated scaffold application into a Web application that functions as required. The reason for this is a combination of the highly complex code generated by Roo and the lack of comprehensive documentation on it.
Man muss also was über Acitivities, Places, RequestFactory und modules wissen, um weiterzukommen - tough, Digger, finden auch andere.
Also liest du hier RequestFactory, hier Activities und Places, und hier sowieso IBM.
Aber ich vertraue auf Cengiz und versuche eine Anpassung durch ein neues Modul:
Erstmal neuen Finder dazu bauen - vorerst easy mit einem Like und einem Equals:
~.server.domain.MediaItem roo> finder add --finderName findMediaItemsByTitleLikeAndMediaKind
Die GUI wird erweitert um einen Menu-Eintrag mit der Suchanfrage: (Keine Sorge, kann man noch selbst beschriften...)
No API environment is registered for this thread.
mvn gae:run
JPA query to GAE ersetzt mir roo auch nicht; aber man kann ja die generierten Finder in die Hauptklasse "pushen" und dann anpassen:
Alter, SCARY - in einem Forum auf Dzone hat der irre Norweger gepostet...
Sonntag, Oktober 23, 2011
GWT spring roo ts
Ich will Spring IOC, DI und frameworks. Ich will eine Java-Umgebung als Hoster, möglichst kostengünstig: GAE. Ich will GWT und GAE und CRUD. ohne dafür GUIs bauen zu müssen. Ich will die neuesten GWT-Sachen (Eventbus, Activity, Places). Ich will mich mit einer einfachen DSL auf die Domäne konzentrieren, nicht auf den Request-Zyklus oder Persistenz.
Aber wie immer gilt auch hier: Besser man ist mal zu Fuß den Weg gegangen, eine Web 2.0 App mit GAE, GWT, Spring zu bauen, ansonsten steht man bei den ersten roo-Fehler im Regen. Und man sollte das "roo-Undo" mit git unbedingt nutzen. Sonst ist schnell mal was hingeneriert, was keiner braucht... In jeden Fall ist post-generatem immer mal gut, zu wissen was roo so alles raushaut.
Basic building blocks:
Editor Framework
You might be wondering how the generated application reads and
writes entity objects from and to the view. It is all hidden away inside
the GWT Editor Framework, which provides the functionality implicitly,
using the marker interface pattern.
The RequestFactory
The RequestFactory and JPA provide an easy way to build
data-oriented CRUD applications and together make up the data-access
layer of our Roo-generated application.Built to complement the
service-oriented GWT RPC and not replace it, the data-oritented
RequestFactory is GWT's new mechanism that provides more efficient
client/server data transfer. It allows us to define data-centric Entity
classes on the server side and to define business logic with EntityProxy
on the client side.
Entity
Entity s are server-side Data Access Objects (DAO) in our
RequestFactory mechanism and should be placed in a package that will not
be converted to JavaScript by GWT.
EntityProxy
Objects that implement the EntityProxy interface are Data Transfer
Objects (DTO) and client-side representations of corresponding Entity
objects. The exclusive use of EntityProxy interface on the client side
relieves us from the requirement of writing GWT-compatible code in our
Entity implementations.The BaseProxy interface, along with others that
extend EntityProxy interface, enables RequestFactory to determine fields
that have changed and send only these changes to the server.
Activity Pattern
In the application that Roo has generated for us, the Activity is
the implementation of the Presenter component and IsWidget is the
implementation of the View component of our MVP pattern.
Activity
An Activity is completely isolated from the view and contains no
widgets or UI code. This isolation greatly simplifies the testing of
logic contained within an Activity.
Place
A Place is a bookmarkable state for a Web application. An Activity
needs a corresponding Place in order to be accessible via a URL. It has
an associated PlaceTokenizer that serializes the Place's state to a URL
token.
PlaceController
The PlaceController manages the current Place and navigation
between Places in a Web application and makes the back-button and
bookmarks work as users would expect.
Also ans Werk mit meinem Medienboten-Projekt und diesem Script:
project --topLevelPackage de.tixus.roo.mb
persistence setup --provider DATANUCLEUS --database
GOOGLE_APP_ENGINE
enum type --class ~.shared.domain.Gender
enum constant --name MALE
enum constant --name FEMALE
enum type --class ~.shared.domain.TypeOfPerson
enum constant --name CUSTOMER
enum constant --name STAFF
enum type --class ~.shared.domain.MediaKind
enum constant --name BOOK
enum constant --name BIGFONT
enum constant --name CD
entity --class ~.server.domain.Person --testAutomatically
field string --fieldName displayName --notNull
field string --fieldName userName --sizeMin 3 --sizeMax 30
--notNull
field string --fieldName firstName
field string --fieldName lastName
field reference --type Person staff
field enum --fieldName gender --type ~.shared.domain.Gender
field enum --fieldName type --type ~.shared.domain.TypeOfPerson
field boolean --fieldName admin --notNull
entity --class ~.server.domain.MediaItem --testAutomatically
field string --fieldName mediaNumber --notNull
field string --fieldName title --notNull
field string --fieldName shortDescription
field number --type java.lang.Integer publicationYear
field enum --fieldName mediaKind --type ~.shared.domain.MediaKind
field number --type java.lang.Integer amount
field reference --type ~.server.domain.Person lentTo
web mvc setup
web mvc all --package ~.web
-- web mvc language --code de
security setup
gwt setup
logging setup --level DEBUG
>mvn gwt:run
Probleme:
Plugin execution not covered by lifecycle configuration: org.datanucleus:maven-datanucleus-plugin:1.1.4:enhance (execution: default, phase: compile) pom.xml /mb line 710 Maven Project Build Lifecycle Mapping Problem
->Use quick fix
Project configuration is not up-to-date with pom.xml. Run project configuration update mb line 1 Maven Configuration Problem
->maven->update project configuration
->Add roo project nature
Enables roo shell and allows for Google WebApplication
->Run As ... Google WebApplication -Tataa:
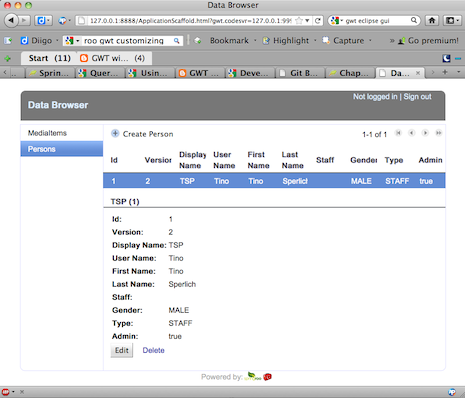
Donnerstag, Juli 28, 2011
Tools on *nix
Nachdem ich hier über den Systemwechsel und die damit verlorenen Tools gejammert habe, hat sich alles wieder eingespielt auf der neuen Umgebung:
Prune sieht vernünftig aus als Geosetter-Ersatz für KML/KMZ-Dateien.

Sitecopy macht einen tollen weil unkomplizierten Eindruck: update Kommando raus und Verzeichnisse werden abgeglichen - geht nicht einfacher!
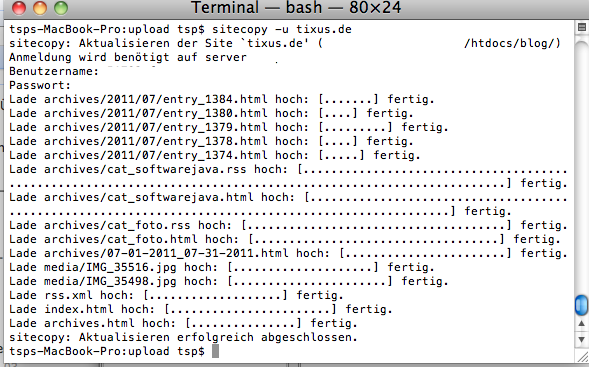
Mittwoch, Juli 27, 2011
GWT secured
 Mann mann mann - choose your filter carefully: Ich brauche einige
Versuche und kostbare Zeit um
die GWT-SpringSecurity-Verknüpfung hinzukriegen - nun gehts:
Mann mann mann - choose your filter carefully: Ich brauche einige
Versuche und kostbare Zeit um
die GWT-SpringSecurity-Verknüpfung hinzukriegen - nun gehts:
Das hier verlangt für den allgemeinen Zugriff "/" (also auch die Anmeldungsseite!) einen anonymen User, sonst einen angemeldeten User und für "/mbopac/admin" eben einen Admin:
<http access-denied-page="/access-denied.html">
<intercept-url pattern="/" access="IS_AUTHENTICATED_ANONYMOUSLY"
/>
<intercept-url pattern="/mbopac/admin/**" access="ROLE_ADMIN" />
<intercept-url pattern="/**" access="ROLE_USER" />
<form-login login-page="/login.html"
default-target-url="/Mbopac.html"
always-use-default-target='true' />
</http>
Das o.g. Tutorial ist ganz nett weil es Spring Security und GWT vereint, aber es läuft nicht auf der AppEngine: Das Problem ist die Spring autogenerierte Login-Seite, eine einfache eigene Seite "login.html" und Konfiguration in applicationContext.xml hilft dann endlich:
<html>
<head>
<meta http-equiv="content-type" content="text/html;
charset=UTF-8">
<link type="text/css" rel="stylesheet" href="Mbopac.css">
<title>OPAC Medienboten Bücherhallen Hamburg</title>
</head>
<body>
<h2>Bitte melden Sie sich an.</h2><br>
<form method="POST" action="j_spring_security_check">
Benutzer: <input type="text" name="j_username"><br>
Passwort: <input type="password" name="j_password"><br>
<input type='checkbox' name='_spring_security_remember_me'/> Auf
diesem Computer eingeloggt bleiben?.<br>
<input type="submit" value="Anmelden >>">
</form>
</body>
</html>
Mit diesem Tipp und einer Ableitungsebene mehr ist dann auch Springkonfiguration mit autowire erhältlich:
public class SpringGwtServlet extends RemoteServiceServlet {
@Override
public void init(ServletConfig config) throws ServletException {
super.init(config);
WebApplicationContextUtils.
getRequiredWebApplicationContext(getServletContext()).
getAutowireCapableBeanFactory().
autowireBean(this);
}
}
 Das hier (Double brace initialization) mag ja nett aussehen ist
aber too "cute":
Das hier (Double brace initialization) mag ja nett aussehen ist
aber too "cute":
final Set<String> rolesAdmin = new HashSet<String>() {
{ add(CustomAuthenticationProvider.ROLE_USER);add(CustomAuthenticationProvider.ROLE_ADMIN);
} };
Es ist hat eben die Implementierungsdetails, dass das erste Klammerpaar eine anonyme Innerclass erzeugt und das zweite Paar einen static initializer deklariert: Somit ist die Klasse unbekannt wird im Serialisierungskosmos von GWT hiermit quittiert:
[ERROR] javax.servlet.ServletContext log: Exception while
dispatching incoming RPC call
com.google.gwt.user.client.rpc.SerializationException: Type
'de.tixus.mb.opac.server.DataImporter$1' was not included in the set of
types which can be serialized by this SerializationPolicy or its Class
object could not be loaded. For security purposes, this type will not be
serialized.: instance = [ROLE_ADMIN, ROLE_USER]
Dienstag, Juli 26, 2011
WhenType?
 Ich bin immer wieder fasziniert von solchen Beiträgen, wenn jemand
kleine, scheinbar simple Wahrheiten so formuliert und kombiniert, dass
sie etwas Neues ergeben: Martin
Fowlers schon älterer Artikel zur Frage, wann man einen
Typ/Klasse erstellen sollte, statt bei Primitiven oder allzu generischen
Typen zu bleiben.
Ich bin immer wieder fasziniert von solchen Beiträgen, wenn jemand
kleine, scheinbar simple Wahrheiten so formuliert und kombiniert, dass
sie etwas Neues ergeben: Martin
Fowlers schon älterer Artikel zur Frage, wann man einen
Typ/Klasse erstellen sollte, statt bei Primitiven oder allzu generischen
Typen zu bleiben.
When should you make your own type? To begin with, make a type if
it will have some special behavior in its operations that the base type
doesn’t have.
...
Often you’ll find things such as product
codes that are numeric in form. However, even though they look like a
number, they don’t behave like one. Nobody needs to do arithmetic on
product codes— with a special type you can avoid bugs.
...
Even
if a currency code looks like a string, if it doesn’t behave like one,
it should get a different type. Look at the string’s interface and ask
how much of it applies to a currency code? If most of it doesn’t, then
that’s a good argument for a new type.
...
Indeed,
communication is one of the biggest reasons to use a type. If you have a
method that expects to take a cur- rency parameter, you can communi-
cate this more clearly by having a currency type and using it in the
method declaration.
Eine Übersicht aller Perlen von ihm gibts hier:Immer mal lesen!
Samstag, Juli 02, 2011
Watch your packages
 Dieser Mist hat mich einen schönen ruhigen Vormittag gekostet, ohne dass
ich vorangekommen wäre - grrrh:
Dieser Mist hat mich einen schönen ruhigen Vormittag gekostet, ohne dass
ich vorangekommen wäre - grrrh:
15:27:00.763 [ERROR] [mbopac] Failed to create an instance of
'de.tixus.mb.opac.client.MbopacMainView' via deferred binding
java.lang.RuntimeException: Deferred binding failed for
'de.tixus.mb.opac.client.PersistenceService' (did you forget to inherit
a required module?)
at
com.google.gwt.dev.shell.GWTBridgeImpl.create(GWTBridgeImpl.java:53)
at com.google.gwt.core.client.GWT.create(GWT.java:98)
at
de.tixus.mb.opac.client.MbopacMainView.<init>(MbopacMainView.java:57)
Und was ist das PROBLEM, gwt?
Erst meinte ich oberschlau, dass man auf die Packages achten muss:
Alles was der Client benötigt und kennen muss, muss auch im client-zugreifbaren package definiert sein; der Pfad dafür wird hier gesetzt.
Application.gwt.xml <!-- Specify the paths for translatable code --> <source path='client' /> <source path='shared' />
Dazu gehört alles, was im (Client-)Interface PersistenceService referenziert wird:
package de.tixus.mb.opac.client;
@RemoteServiceRelativePath("greet")
public interface PersistenceService extends RemoteService {
...
MediaItem lend(String mediaNumber, Person person, Boolean isOverride) throws MediaItemAlreadyLentException;
...
Das war leider doch nicht das Problem, sondern der fehlende Default-Constructor in einer Exception! Den habe ich versehentlich überschrieben, als ich beim Refactoring einen neuen Constructor brauchte:
public class MediaItemAlreadyLentException extends RuntimeException {
private Person person = null;
private static final long serialVersionUID = 1L;
public MediaItemAlreadyLentException() {
}
public MediaItemAlreadyLentException(final Person person) {
this.person = person;
}
}
Die OPAC-Anwendung nimmt jedoch Formen an: Nun kann man bereits den Katalog durchsuchen, Medien ausleihen und zurückgeben. Es fehlt zum ersten Start noch die Suche nach dem Kunden eines ausgeliehenen Mediums sowie eine Einschränkung der Suche auf noch nie ausgeliehene Titel für einen Kunden - man will schliesslich immer mal was Neues lesen.
Donnerstag, Mai 05, 2011
MBP 2
 Mein zweiter Versuch mit nem MBP ist vieel besser! Mattes Hires-Display,
und gleich mal wieder den Hibernate-Modus auf den Windows-bekannten
echten Ruhezustand gebracht - dauert beim Aufwachen ca. 20s, der Rechner
ist zwischendurch aber wirklich aus und nicht auf Batterie, heisst beim
Mac "always safe-sleep with secure virtual memory":
Mein zweiter Versuch mit nem MBP ist vieel besser! Mattes Hires-Display,
und gleich mal wieder den Hibernate-Modus auf den Windows-bekannten
echten Ruhezustand gebracht - dauert beim Aufwachen ca. 20s, der Rechner
ist zwischendurch aber wirklich aus und nicht auf Batterie, heisst beim
Mac "always safe-sleep with secure virtual memory":
sudo pmset -a hibernatemode 5
Ansonsten schön schnelle *nix-Maschine, git und strings und ls alles da!
Gaaanz wichtig bei Hires-Displays - die Auflösung versaut die Augen, wenn man den Standard-Font von 10-13px belässt. Viele Anwendungen benutzen die System-Vorgaben, welche man sinnigerweise nicht besonders gut mit den System-Tools ändern kann - aber Tinkertool ist das TweakUI fürn Mac:
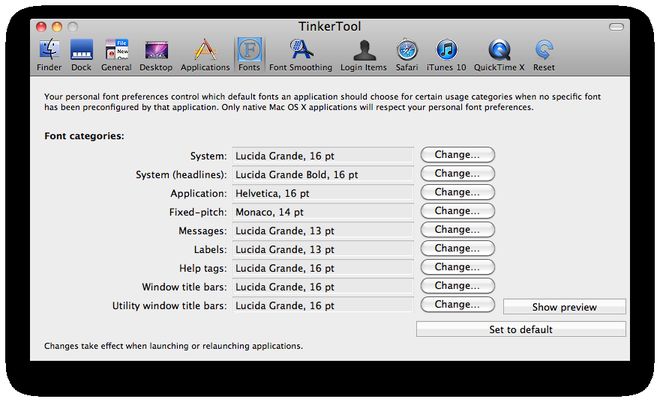
Alles auf z.B. 16pt ändern und Anwendung neustarten - voila!
Aber man verzweifelt eher an liebgewonnenen Programme für Alltagsaufgaben - Total Commander und das Directory-Sync waren eine super Sache - der für Mac verfügbare Filezilla kann auch Ordner abgleichen aber nicht rekursiv.
Zum Glück erinnere ich mich daran, dass IrfanView ein Windows -Clone von XnView ist - dieses gibts für Mac auch und es funktioniert wie gewohnt - toll!
Freitag, April 29, 2011
MBP 1
 Ok, ich habe es getan: Ein neues Notebook muss her, also geschaut und
verglichen - die Überraschung war, dass ein MBP mit Core i7 und 15 Zoll
dann preislich sogar mit Lenovo und Konsorten mithalten kann. Also ein
"MACBOOK PRO 15" QUAD-CORE I7 2000 SD DEUTSCH, 4 GB RAM, 500 GB HD" bei
Gravis gekauft. Schick, schnell und spiegelnd: Das Foto ist nach dem
Aufklappen entstanden - wie kann man sowas herstellen? Ok, nachdem ich
so eine Diskussion von Apple-Jüngern gelesen habe, hab ich
schon bereut, mein Geld dahin getragen zu haben - wie kann man im
wahrsten Sinne des Wortes so oberflächlich sein? Andererseits - kann man
einen Hersteller ablehnen, aber seine Waren kaufen? Hier gibts nen guten
Eindruck von beiden Modellen... Da ich aber die 150 EUR Aufpreis für
die entspiegelte Version sparen wollte, bin ich mit dem o.g. nach Hause.
Alles installiert und rumgespielt, aber am Sonntag mit mulmigem Gefühl
wieder vorsichtig eingepackt und Montag zu Gravis: "Äh, ich möchte den
gern gegen den teureren umtauschen" Gravis in Ehren, man lässt sich
darauf ein und nun warte ich auf die neue Lieferung - einen Geldabzug
wirds wohl geben weils nun keine Neuware mehr ist - mal sehen.
Ok, ich habe es getan: Ein neues Notebook muss her, also geschaut und
verglichen - die Überraschung war, dass ein MBP mit Core i7 und 15 Zoll
dann preislich sogar mit Lenovo und Konsorten mithalten kann. Also ein
"MACBOOK PRO 15" QUAD-CORE I7 2000 SD DEUTSCH, 4 GB RAM, 500 GB HD" bei
Gravis gekauft. Schick, schnell und spiegelnd: Das Foto ist nach dem
Aufklappen entstanden - wie kann man sowas herstellen? Ok, nachdem ich
so eine Diskussion von Apple-Jüngern gelesen habe, hab ich
schon bereut, mein Geld dahin getragen zu haben - wie kann man im
wahrsten Sinne des Wortes so oberflächlich sein? Andererseits - kann man
einen Hersteller ablehnen, aber seine Waren kaufen? Hier gibts nen guten
Eindruck von beiden Modellen... Da ich aber die 150 EUR Aufpreis für
die entspiegelte Version sparen wollte, bin ich mit dem o.g. nach Hause.
Alles installiert und rumgespielt, aber am Sonntag mit mulmigem Gefühl
wieder vorsichtig eingepackt und Montag zu Gravis: "Äh, ich möchte den
gern gegen den teureren umtauschen" Gravis in Ehren, man lässt sich
darauf ein und nun warte ich auf die neue Lieferung - einen Geldabzug
wirds wohl geben weils nun keine Neuware mehr ist - mal sehen.
Sonntag, Januar 23, 2011
Widgettime: Tatort+Privatleihe
Es gibt Fixpunkte im erwachsenen Leben, bei uns gehört der Tatort dazu. Und dank Tatort-Fans verpassen wir nie wieder eine Wiederholung, denn so richtig sind wir erst seit ~4 Jahren dabei.

 Eine andere schöne Sache ist eine Auflistung unserer DVDs - so könnt ihr
sie gerne mal (kostenlos natürlich) ausleihen, wenn ihr nichts mehr zu
kucken habt. Aktuell sind nämlich die DVD-Boxen "Loriot", "Kommissarin
Lund -Das Verbrechen I" sowie Pedro
Almodovar "Die große Edition" im Angbot.
Eine andere schöne Sache ist eine Auflistung unserer DVDs - so könnt ihr
sie gerne mal (kostenlos natürlich) ausleihen, wenn ihr nichts mehr zu
kucken habt. Aktuell sind nämlich die DVD-Boxen "Loriot", "Kommissarin
Lund -Das Verbrechen I" sowie Pedro
Almodovar "Die große Edition" im Angbot.
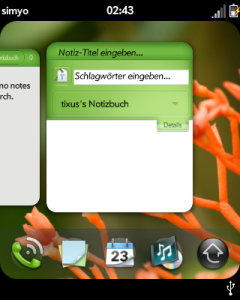
 Ich bin weiter begeistert vom webOS und verwirrt von meiner Prägung
durch frühere Handy-Betriebssysteme: Wie viel leichter kann man es bitte
noch machen einen Screenshot zu erstellen,
Ich bin weiter begeistert vom webOS und verwirrt von meiner Prägung
durch frühere Handy-Betriebssysteme: Wie viel leichter kann man es bitte
noch machen einen Screenshot zu erstellen, 

 Es ist immer wieder interessant, den richtigen Cracks hinterher zu
lesen: David Gelernter und Eric Freeman, dieser Eintrag aus
Es ist immer wieder interessant, den richtigen Cracks hinterher zu
lesen: David Gelernter und Eric Freeman, dieser Eintrag aus 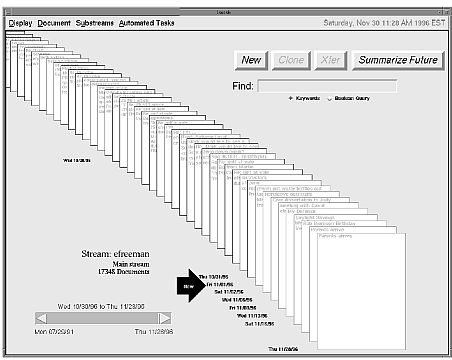

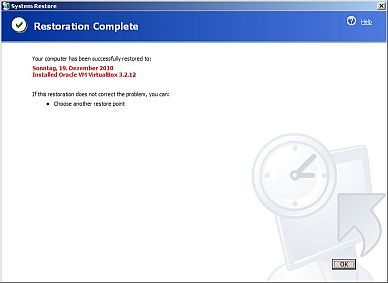 Wie immer stehen längliche Downloads an: Die offizielle Seite verlangt
auch noch eine VirtualBox-Installation (für den Emulator?), seis drum.
Die VirtualBox 3.2.12 crashed schon mal WinXP, na herrlich - dann
probier ich mal das System Restore - läuft! Version 3.2.10 funktioniert
besser.
Wie immer stehen längliche Downloads an: Die offizielle Seite verlangt
auch noch eine VirtualBox-Installation (für den Emulator?), seis drum.
Die VirtualBox 3.2.12 crashed schon mal WinXP, na herrlich - dann
probier ich mal das System Restore - läuft! Version 3.2.10 funktioniert
besser.



 Leider gibt es nicht den einen App-Shop, sondern 1000
Leider gibt es nicht den einen App-Shop, sondern 1000 
 Dabei
Dabei 
 Meine zweite Computer-Tat diese Woche war die Installation von XP auf
einem Mac. Das zu lösende Problem war jedoch die Installation eines
Dreamweavers auf einem Mac, wenn man nur eine Windowsversion hat. Jetzt
kann man eine Menge über
Meine zweite Computer-Tat diese Woche war die Installation von XP auf
einem Mac. Das zu lösende Problem war jedoch die Installation eines
Dreamweavers auf einem Mac, wenn man nur eine Windowsversion hat. Jetzt
kann man eine Menge über 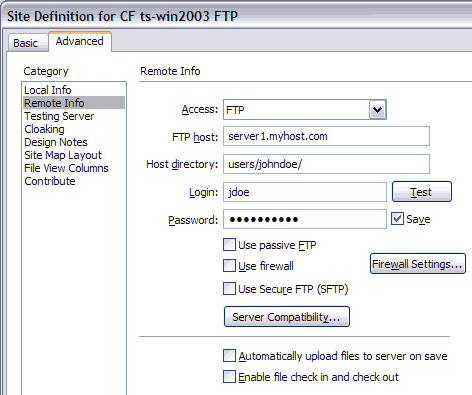
 Executable Specifications: (Vorsicht Binse) Nur ein Teil der Erstellung
von Software ist die Programmierung. Viel Zeit und Denkarbeit geht in
die Spezifikation bzw. Anforderungsanalyse (Requirements). Das Resultat
ist häufig ein unglaublicher Wust an Text, manchmal mit einer Grafik,
selten mit Beispielen. Und bei allen besten Absichten der Schreiber ist
die Spez voll von mehrdeutigen Formulierungen und leer von
"Selbstverständlichkeiten" - in letzter Zeit habe ich es mehrfach
erlebt, dass nach der Implementierung bei den ersten Tests absolut
grundlegende Missverständnisse bgzl. der Funktion auftraten. Kann das
mit Exectuable Specifications/User written Acceptance Tests besser sein?
Executable Specifications: (Vorsicht Binse) Nur ein Teil der Erstellung
von Software ist die Programmierung. Viel Zeit und Denkarbeit geht in
die Spezifikation bzw. Anforderungsanalyse (Requirements). Das Resultat
ist häufig ein unglaublicher Wust an Text, manchmal mit einer Grafik,
selten mit Beispielen. Und bei allen besten Absichten der Schreiber ist
die Spez voll von mehrdeutigen Formulierungen und leer von
"Selbstverständlichkeiten" - in letzter Zeit habe ich es mehrfach
erlebt, dass nach der Implementierung bei den ersten Tests absolut
grundlegende Missverständnisse bgzl. der Funktion auftraten. Kann das
mit Exectuable Specifications/User written Acceptance Tests besser sein?
 Ich war allein bei
Ich war allein bei  Es können einfach nicht alle Firmen nur die 10% Besten eines Jahrgangs
bekommen. Auch wenn das den Anschein der frühen Kapitulation auf dem
Markt der Talente hat, ist es doch realistisch. Man kann natürlich, wie
es
Es können einfach nicht alle Firmen nur die 10% Besten eines Jahrgangs
bekommen. Auch wenn das den Anschein der frühen Kapitulation auf dem
Markt der Talente hat, ist es doch realistisch. Man kann natürlich, wie
es  Man lernt ja immer ne Menge Neues, wenn man mal was Altes machen will;
heute: Windows XP installieren. Ok, gültige Lizenz und bootfähige CD hab
ich noch, klick, ist ne Weile her, aber Radfahren verlernt man ja nicht,
booten, schnipp -
Man lernt ja immer ne Menge Neues, wenn man mal was Altes machen will;
heute: Windows XP installieren. Ok, gültige Lizenz und bootfähige CD hab
ich noch, klick, ist ne Weile her, aber Radfahren verlernt man ja nicht,
booten, schnipp -  Der harte Weg war dann: Installation eines Windows XP, das nach 30 Tagen
aktiviert werden muss, dann die o.g. CD eingelegt und XP davon noch
einmal installiert, mit Lizenz und so. Nun hat Suse mein Laptop, das
Der harte Weg war dann: Installation eines Windows XP, das nach 30 Tagen
aktiviert werden muss, dann die o.g. CD eingelegt und XP davon noch
einmal installiert, mit Lizenz und so. Nun hat Suse mein Laptop, das  Er fragt, wozu man ohne Grund einfach immer ein Interface erstellt,
selbst wenn es niemals mehr als genau eine Implementierung geben wird.
Das verschmutzt nicht nur den Namensraum ("ICustomer" oder
"CustomerImpl" wenn "Customer" reichen würde) und es bringt fürs Testen
auch keine Vorteile, denn auch Klassen kann man mocken (ok, sie dürfen
nur nicht final sein).
Er fragt, wozu man ohne Grund einfach immer ein Interface erstellt,
selbst wenn es niemals mehr als genau eine Implementierung geben wird.
Das verschmutzt nicht nur den Namensraum ("ICustomer" oder
"CustomerImpl" wenn "Customer" reichen würde) und es bringt fürs Testen
auch keine Vorteile, denn auch Klassen kann man mocken (ok, sie dürfen
nur nicht final sein).
 SOA ist bei Managern beliebt, in der Praxis aber nicht so einfach bzw.
leichtgewichtig: Datentypen konvertieren zwischen .NET und Java ist
hakelig. Wenn man es ROA nennt (Resource oriented architecture) und REST
over HTTP macht, kommt man weiter: String/JSON läßt sich gut
konvertieren.
SOA ist bei Managern beliebt, in der Praxis aber nicht so einfach bzw.
leichtgewichtig: Datentypen konvertieren zwischen .NET und Java ist
hakelig. Wenn man es ROA nennt (Resource oriented architecture) und REST
over HTTP macht, kommt man weiter: String/JSON läßt sich gut
konvertieren.
 Und das klingt auch vertraut - die gute alte Servlet-API im
WebContainer-Layout:
Und das klingt auch vertraut - die gute alte Servlet-API im
WebContainer-Layout:
{kind=link}